由编译优化带来的boot跳转问题
本文分析说明编译优化对bootloader跳转的影响以及处理方法。
前两天刘兄发现一个隐藏在bootloader内的bug,并给出了最稳妥的解法。觉得该问题比较有意思,于是收集了相关资料进行分析供各位参考。
问题 链接到标题
Cortex-M7 由bootloader将引导xip image,在设置MSP后跳转前CPU挂掉。跳转代码如下
void boot_jump_run(void)
{
pfnImage reset_handle;
//一些状态通知代码
....
SCB_CleanDCache();
//取得要跳转的地址
reset_handle = (pfnImage)(*IMAGE_RESET_ADDRESS);
__ISB();
__disable_irq();
SysTick->CTRL &= ~SysTick_CTRL_ENABLE_Msk;
/* Disable NVIC interrupts */
for (uint8_t i = 0; i < ARRAY_SIZE(NVIC->ICER); i++) {
NVIC->ICER[i] = 0xFFFFFFFF;
}
/* Clear pending NVIC interrupts */
for (uint8_t i = 0; i < ARRAY_SIZE(NVIC->ICPR); i++) {
NVIC->ICPR[i] = 0xFFFFFFFF;
}
//设置MSP
__set_MSP(*MSP_STORE_ADDRESS);
__set_CONTROL(0x00);
//执行跳转
reset_handle();
}
这段代码原本用来正常,这次将MSP修改到RAM的顶端就出现了异常,看下反汇编
0x600056fa <+166>: msr MSP, r3 //设置MSP
0x600056fe <+170>: movs r3, #0
0x60005700 <+172>: msr CONTROL, r3
0x60005704 <+176>: mov r3, r4
0x60005706 <+178>: ldmia.w sp!, {r4, r5, r6, lr} //问题出在这里,跳转前在出栈
0x6000570a <+182>: bx r3 //跳转
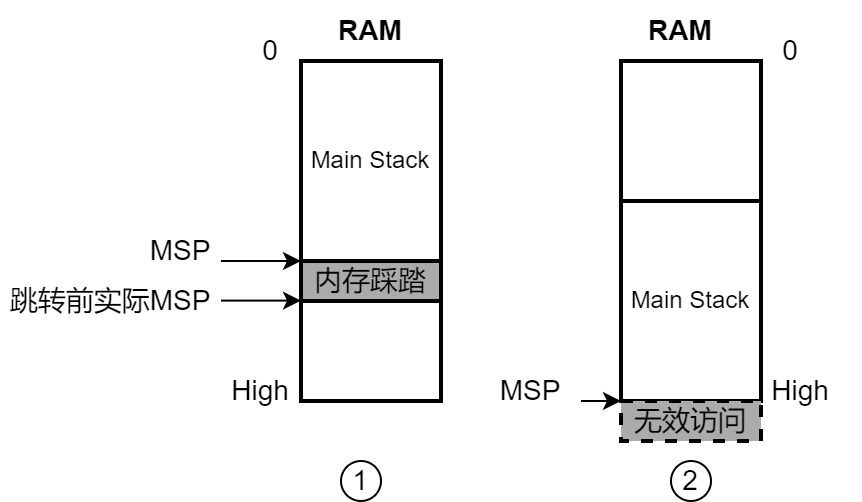
问题就出在跳转前出栈,出栈时sp是递减,当MSP指向RAM顶端时,出栈sp递减访问范围将会超出RAM,无效地址导致CPU异常, 见下图2。
原本MSP不是指向RAM顶端,因此跳转没发现问题,加上原本的MSP指向内存的前面是有效内存,跳转后不会立即出问题,但在使用堆栈时会发生图1中阴影内存踩踏部分被入栈的数据改写,如果该部分已被其它地方使用将导致异常。
原因 链接到标题
原因分析 链接到标题
单从C语言看,执行reset_handle前没有什么特殊操作,为什么在编译后会插入一条出栈指令呢?基本上可以猜到是编译优化的问题,于是降低优化等级重新编译,果然就正常了
0x600056fa <+166>: msr MSP, r3 //设置MSP
0x600056fe <+170>: movs r3, #0
0x60005700 <+172>: msr CONTROL, r3
0x60005704 <+176>: blx r4 //跳转
0x60005706 <+178>: pop {r4, r5, r6, pc} //出栈在这里
是什么优化导致出栈被提前到跳转前呢?我们再看看boot_jump_run的全部反汇编
Dump of assembler code for function boot_jump_run:
0x60005654 <+0>: ldr r1, [pc, #176] ; (0x60005708 <boot_jump_run+180>)
0x60005656 <+2>: movs r0, #16
0x60005658 <+4>: push {r4, r5, r6, lr} #这里lr保存了boot_jump_run的返回地址,接下来调用report_status需要占用lr,因此要入栈保护
0x6000565a <+6>: bl 0x600059f0 <>
....
0x600056fa <+166>: msr MSP, r3 //设置MSP
0x600056fe <+170>: movs r3, #0
0x60005700 <+172>: msr CONTROL, r3
0x60005704 <+176>: mov r3, r4
0x60005706 <+178>: ldmia.w sp!, {r4, r5, r6, lr} //先出栈到lr,也就是boot_jump_run的返回地址
0x6000570a <+182>: bx r3 //再调用reset_handle
从汇编的注释分析我们知道在调用reset_handle前, lr内已经放的是boot_jump_run的返回地址,再继续看调用reset_handle汇编指令是bx,也就是说不会做pc+4->lr的动作,lr一直保存的是boot_jump_run的返回地址,因此在reset_handle执行完后使用指令ret返回时,跳到的时boot_jump_run的返回地址,再看看我们C的写法
void boot_jump_run(void)
{
pfnImage reset_handle;
...
//执行跳转
reset_handle();
}
reset_handle刚好是boot_jump_run最后一个调用函数,编译器就做了上面流程的优化,叫做尾调用优化.
尾调用优化 链接到标题
什么是尾调用 链接到标题
尾调用是指某个函数的最后一步是调用另一个函数,下面的goo是一个典型的尾调用
int foo(int x){
x++;
return goo(x);
}
注意尾调用只要求是函数的最后一步而并不一定是出现在函数尾部,例如下面的moo和noo都是尾调用
int foo(int x) {
if (x > 0) {
return moo(x)
}
return noo(x);
}
下面的情况都不是尾调用
// 情况一
int foo(int x){
int y = goo(x);
return y;
}
// 情况二
int foo(int x){
return goo(x) + 1;
}
尾调用优化有下面两个好处
- 被调用函数执行完后,不需要再跳回调用函数
- 由于被调用函数是最后一条指令,调用函数的堆栈不需要再保存,被调用函数直接用调用函数的栈,这样可以有效的节省内存空间,并且可以防止出现栈溢出
优化控制方式 链接到标题
在gcc中O1以上的优化就会启用尾调用优化,下面两个编译选项分别可以启用和关闭尾调用优化
-foptimize-sibling-calls
-fno-optimize-sibling-calls
原本只是知道尾调用优化会用到尾递归的代码写法用于节省堆栈,但在本案中对未递归也生效,但看看gcc文档的说明
-foptimize-sibling-calls Optimize sibling and tail recursive calls.
支持同级的尾优化,做得够狠。
ARM的尾调用优化 链接到标题
对于尾调用优化的两个好处我们主要看重的是节省堆栈,但实际如果局部变量占用了堆栈反倒不进行同级尾调用优化:
//测试代码
void boot_jump_run(void)
{
pfnImage reset_handle;
char test[20] = {0};
printf("%p", test);
....
__set_MSP(*MSP_STORE_ADDRESS);
__set_CONTROL(0x00);
reset_handle();
}
以上代码反汇编
Dump of assembler code for function boot_jump_run:
0x60005700 <+0>: push {r4, r5, r6, lr}
0x60005702 <+2>: movs r4, #0
0x60005704 <+4>: sub sp, #24 #堆栈上开辟局部变量数组test空间
0x60005706 <+6>: movs r2, #16
...
0x600057bc <+188>: msr MSP, r3
0x600057c0 <+192>: movs r3, #0
0x600057c2 <+194>: msr CONTROL, r3
0x600057c6 <+198>: blx r4 # 未进行尾调用优化, 如果进行,在这之前就应该放出堆栈
0x600057c8 <+200>: add sp, #24
0x600057ca <+202>: pop {r4, r5, r6, pc}
因此可见在cortex-m7下的同级尾调用优化是一个鸡肋,并没有获得多大好处
解决方法 链接到标题
知道了原因就容易解决了,下面几种解决方法
方法1:使用汇编精准控制 链接到标题
作为跳转,我们知道只是要跳转到指定位置执行,SP也被重新初始化,原来的堆栈已经没有意义,直接使用汇编控制跳转,这也是最安全没有歧义的方法,也是最推荐的方法.
void boot_jump_run(void)
{
pfnImage reset_handle;
SCB_CleanDCache();
reset_handle = (pfnImage)(*IMAGE_RESET_ADDRESS);
__ISB();
__disable_irq();
SysTick->CTRL &= ~SysTick_CTRL_ENABLE_Msk;
/* Disable NVIC interrupts */
for (uint8_t i = 0; i < ARRAY_SIZE(NVIC->ICER); i++) {
NVIC->ICER[i] = 0xFFFFFFFF;
}
/* Clear pending NVIC interrupts */
for (uint8_t i = 0; i < ARRAY_SIZE(NVIC->ICPR); i++) {
NVIC->ICPR[i] = 0xFFFFFFFF;
}
__set_MSP(*MSP_STORE_ADDRESS);
__set_CONTROL(0x00);
//嵌入汇编跳到指定位置运行
__asm volatile ("BX %0" : : "r" (reset_handle) : );
}
方法2:降低优化等级 链接到标题
三种方式 1.可以在编译的时候指定使用Og或以下的优化等级,但这样打击面太广。
-Og
2.可以在编译的时候维持高的优化等级单独关闭尾调用优化。
-Os -fno-optimize-sibling-calls
3.另外可以进一步缩小范围,只让boot_jump_run不进行尾调用优化
#pragma GCC push_options
#pragma GCC optimize ("no-optimize-sibling-calls")
void boot_jump_run(void)
{
pfnImage reset_handle;
...
__set_MSP(*MSP_STORE_ADDRESS);
__set_CONTROL(0x00);
reset_handle();
}
//#pragma GCC pop_options
方法3:破坏尾调用 链接到标题
是尾调用引起的,我们就让跳转不是尾调用方式
void boot_jump_run(void)
{
pfnImage reset_handle;
...
__set_MSP(*MSP_STORE_ADDRESS);
__set_CONTROL(0x00);
reset_handle();
__builtin_unreachable();
}
总结 链接到标题
涉及到底层相关的流程为了不被编译器引入歧义,最好使用汇编进行精确控制, 因此推荐使用方法1。但一些情况下为了多架构的可移植性,想要保留C代码形式的跳转方式也会采用方法2,例如mcuboot就是使用的Og优化等级。
GCC优化等级 链接到标题
分析本案的时候,查了一下Gcc的优化等级这里记录一下
- 可指定优化等级:-O0、-O1、-O2、-O3、-Og、-Os、-Ofast。
- 未指定时则默认为 -O0,无优化。O后面数字越大优化程度越高
- -Og在-O1的基础上,去掉影响调试的优化,最终是为了调试程序,可以使用这个参数。
- -Os在-O2的基础上,去掉会导致最终可执行程序增大的优化,生成小尺寸的可执行文件。
- -Ofast在-O3的基础上,添加了一些非常规优化例如对数学函数等,达到提高执行速度的目的。 使用 gcc -Q –help=optimizers 命令来查询具体做了哪些优化,例如:
gcc -Q --help=optimizers -O2
参考 链接到标题
https://zh.wikipedia.org/wiki/%E5%B0%BE%E8%B0%83%E7%94%A8 https://gcc.gnu.org/onlinedocs/gcc/Optimize-Options.html#Optimize-Options https://www.drdobbs.com/tackling-c-tail-calls/184401756 https://www.pspace.org/a/thesis/baueran_thesis.pdf https://developer.arm.com/documentation/ddi0406/c/Application-Level-Architecture/Instruction-Details/Alphabetical-list-of-instructions/BX https://developer.arm.com/documentation/ddi0406/c/Application-Level-Architecture/Instruction-Details/Alphabetical-list-of-instructions/BLX--register-