Zephyr内核调度之代码分析1--线程流转
本文分析调度列队管理的实现及线程在列队之间流转。
前文参考, 后文内只给出参考序号,参考链接如下: [1] Zephyr内核调度之调度方式与时机 [2] Zephyr内核调度之列队管理算法 [3] Zephyr线程生命周期及状态机 [4] Zephyr线程阻塞和超时机制分析 [5] Zephyr线程优先级简介
注:本系列文章都基于单核CPU进行分析
概述 链接到标题
调度是指计算机中分配工作资源的方法。对于Zephyr来说通过线程调度分配CPU资源,内核对象和软硬件资源绑定通过对内核对象分配达到分配软硬件资源的目的。 因此Zephyr内核调度可以简单的分为下面两部分:
- 确定哪个线程占用CPU
- 确定哪个线程获取内核对象
无论是那种情况调度的对象都是线程,也就是选出线程使用资源。调度执行的过程就是选的过程。 Zephyr内核使用列队来组织管理线程,调度可以被分解为下面几个情况:
- 线程加入到列队中。
- 从列队中选出线程使用资源。
- 从列队中移除线程,不使用资源。
下面就从列队和两个方面进行分析说明.
列队 链接到标题
Zephyr的列队 链接到标题
在Zephyr中有下面2类型的列队:
- 就绪列队: 一个CPU只有一个read_q,用于存放管理已就绪的线程,这些线程等待使用CPU。
- 等待列队:一个内核对象有一个或者多个wait_q, 用于存放等待该内核对象的线程。 宏观的看调度就线程被放入对应的列队,再按照一定的条件从列队中选出占用资源。
Zephyr支持三种方法列队管理方法:
- 单链表
- 红黑树
- 多链表 线程占用CPU三种列队都可以使用,内核对象只能使用单链表和红黑树。Zephyr选择那种列队由配置项决定,编译后不可再修改。关于调度列队的详细内容参考[2]
代码 链接到标题
Zephyr中列队管理的线程其依据线程优先级来进行调度的,优先级高的线程优先获得资源,同等优先级的线程等待得久的优先获得资源。与优先级相关的细节请参考[1]和[5]。 Zephyr使用下面三个宏对就绪列队进行管理:
_priq_run_add //将线程加入列队
_priq_run_remove //将线程中列队中移除
_priq_run_best //检查列队中哪个线程应该被选出占用资源
和调度分解的情况对应就是
- 线程加入到列队中: _priq_run_add
- 从列队中选出线程使用资源:_priq_run_best,_priq_run_remove
- 从列队中移除线程,不使用资源:_priq_run_remove 就绪列队的管理方式可配置为以下三种中的一种:
#if defined(CONFIG_SCHED_DUMB) //单链表
#define _priq_run_add z_priq_dumb_add
#define _priq_run_remove z_priq_dumb_remove
#define _priq_run_best z_priq_dumb_best
#elif defined(CONFIG_SCHED_SCALABLE) //红黑树
#define _priq_run_add z_priq_rb_add
#define _priq_run_remove z_priq_rb_remove
#define _priq_run_best z_priq_rb_best
#elif defined(CONFIG_SCHED_MULTIQ) //多链表
#define _priq_run_add z_priq_mq_add
#define _priq_run_remove z_priq_mq_remove
#define _priq_run_best z_priq_mq_best
#endif
Zephyr使用下面三个宏对就绪列队进行管理:
z_priq_wait_add //将线程加入列队
_priq_wait_remove //将线程中列队中移除
_priq_wait_best //检查列队中哪个线程应该被选出占用资源
和调度分解的情况对应就是
- 线程加入到列队中: z_priq_wait_add
- 从列队中选出线程使用资源:_priq_wait_best,_priq_wait_remove
- 从列队中移除线程,不使用资源:_priq_wait_remove
等待列队的管理方式可配置为以下两种中的一种:
#if defined(CONFIG_WAITQ_SCALABLE) //红黑树
#define z_priq_wait_add z_priq_rb_add
#define _priq_wait_remove z_priq_rb_remove
#define _priq_wait_best z_priq_rb_best
#elif defined(CONFIG_WAITQ_DUMB) //单链表
#define z_priq_wait_add z_priq_dumb_add
#define _priq_wait_remove z_priq_dumb_remove
#define _priq_wait_best z_priq_dumb_best
#endif
由于就绪列队和等待列队的操作都使用的宏,因此可以通过配置就替换掉代码中实际调用的列队管理函数。可以看到就绪列队和等待列队的管理算法都是用的相同的管理函数。 这里的列队管理函数都是标准的数据结构算法,没有必要做详细分析,只分析列队管理中体现队列初始化和线程优先级的部分:
初始化 链接到标题
就绪列队只有一个,其保存在_kernel.ready_q中,在z_sched_init中完成初始化
void z_sched_init(void)
{
#ifdef CONFIG_SCHED_DUMB //单链表,初始化一个双向链表
sys_dlist_init(&_kernel.ready_q.runq);
#endif
#ifdef CONFIG_SCHED_SCALABLE //红黑树,初始化一个红黑树,并指定其lessthan_fn函数
_kernel.ready_q.runq = (struct _priq_rb) {
.tree = {
.lessthan_fn = z_priq_rb_lessthan,
}
};
#endif
#ifdef CONFIG_SCHED_MULTIQ //多链表,初始化多个双向链表
for (int i = 0; i < ARRAY_SIZE(_kernel.ready_q.runq.queues); i++) {
sys_dlist_init(&_kernel.ready_q.runq.queues[i]);
}
#endif
}
等待列队会根据内核对象的数量有多个,在内核对象初始化的时候初始化等待列队,Zephyr初始化内核对象有静态(宏,编译期)和动态(函数,运行期)两种方式 静态:
#ifdef CONFIG_WAITQ_SCALABLE //红黑树
typedef struct {
struct _priq_rb waitq;
} _wait_q_t;
extern bool z_priq_rb_lessthan(struct rbnode *a, struct rbnode *b);
//指定lessthan_fn
#define Z_WAIT_Q_INIT(wait_q) { { { .lessthan_fn = z_priq_rb_lessthan } } }
#else //单链表
typedef struct {
sys_dlist_t waitq;
} _wait_q_t;
//初始化一个waitq双向链表
#define Z_WAIT_Q_INIT(wait_q) { SYS_DLIST_STATIC_INIT(&(wait_q)->waitq) }
#endif
动态
#ifdef CONFIG_WAITQ_SCALABLE
//初始化一个红黑树,并指定其lessthan_fn函数
static inline void z_waitq_init(_wait_q_t *w)
{
w->waitq = (struct _priq_rb) {
.tree = {
.lessthan_fn = z_priq_rb_lessthan
}
};
}
#else /* !CONFIG_WAITQ_SCALABLE: */
//初始化一个双向链表
static inline void z_waitq_init(_wait_q_t *w)
{
sys_dlist_init(&w->waitq);
}
#endif /* !CONFIG_WAITQ_SCALABLE */
单链表 链接到标题
通过z_sched_prio_cmp比较被插入线程的优先级,将线程插入到链表中首个小于其优先级节点的前面,这就保证了:
- 最高优先级始终在链表头
- 后插入的线程在同等优先级线程的后面 详细原理参考[2]
ALWAYS_INLINE void z_priq_dumb_add(sys_dlist_t *pq, struct k_thread *thread)
{
struct k_thread *t;
SYS_DLIST_FOR_EACH_CONTAINER(pq, t, base.qnode_dlist) {
//对比优先级,发现比自己优先级小的节点,将线程插在其前面后立即退出
if (z_sched_prio_cmp(thread, t) > 0) {
sys_dlist_insert(&t->base.qnode_dlist,
&thread->base.qnode_dlist);
return;
}
}
未找到比自己小的优先级
sys_dlist_append(pq, &thread->base.qnode_dlist);
}
struct k_thread *z_priq_dumb_best(sys_dlist_t *pq)
{
struct k_thread *thread = NULL;
//链表头是优先级最高,且最先插入的,因此优先出列队
sys_dnode_t *n = sys_dlist_peek_head(pq);
if (n != NULL) {
thread = CONTAINER_OF(n, struct k_thread, base.qnode_dlist);
}
return thread;
}
红黑树 链接到标题
红黑树的算法是标准实现,其优先级体现是在lessthan_fn上,该函数在初始化的时候已被设置为z_priq_rb_lessthan
bool z_priq_rb_lessthan(struct rbnode *a, struct rbnode *b)
{
struct k_thread *thread_a, *thread_b;
int32_t cmp;
thread_a = CONTAINER_OF(a, struct k_thread, base.qnode_rb);
thread_b = CONTAINER_OF(b, struct k_thread, base.qnode_rb);
//比较优先级
cmp = z_sched_prio_cmp(thread_a, thread_b);
if (cmp > 0) {
return true;
} else if (cmp < 0) {
return false;
} else {
//如果优先级一样,比较order_key,看哪个节点被先插入
return thread_a->base.order_key < thread_b->base.order_key
? 1 : 0;
}
}
红黑树在插入时根据优先级和order_key进行了排序,在查找谁最优先时,就取出排序最低,详细原理参考[2]
struct k_thread *z_priq_rb_best(struct _priq_rb *pq)
{
struct k_thread *thread = NULL;
//取出排序最低的节点
struct rbnode *n = rb_get_min(&pq->tree);
if (n != NULL) {
thread = CONTAINER_OF(n, struct k_thread, base.qnode_rb);
}
return thread;
}
多链表 链接到标题
多链表就是建立了一个以优先级为索引的数组,每个数组对应一个优先级的线程链表,其优先级的体现就是数组的序号,同优先级加入队列的先后是在插入链表的顺序中体现,详细原理参考[2]
ALWAYS_INLINE void z_priq_mq_add(struct _priq_mq *pq, struct k_thread *thread)
{
//优先级决定数组序号
int priority_bit = thread->base.prio - K_HIGHEST_THREAD_PRIO;
//后插入的线程永远在链表尾
sys_dlist_append(&pq->queues[priority_bit], &thread->base.qnode_dlist);
pq->bitmask |= BIT(priority_bit);
}
struct k_thread *z_priq_mq_best(struct _priq_mq *pq)
{
if (!pq->bitmask) {
return NULL;
}
struct k_thread *thread = NULL;
//取出最高优先级的数组元素
sys_dlist_t *l = &pq->queues[__builtin_ctz(pq->bitmask)];
//链表头是最先插入的,所以要优先取出
sys_dnode_t *n = sys_dlist_peek_head(l);
if (n != NULL) {
thread = CONTAINER_OF(n, struct k_thread, base.qnode_dlist);
}
return thread;
}
线程 链接到标题
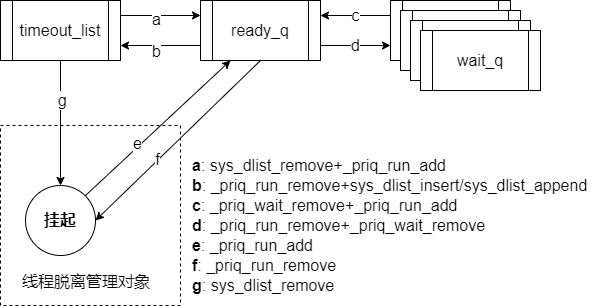
从前面分析我们可以看到,调度的过程其实就是thread的流转过程。被调度的zephyr的线程不只会在就绪列队和等待列队,它会在下面几种状态下流转:
- 就绪: 线程被放入read_q,线程运行时会保持在ready_q中。
- 等待内核对象:线程被放入内核对象的wait_q
- 睡眠:线程被放入timeout_list
- 挂起:线程脱离管理对象
这里我们将read_q, wait_q,timeout_list叫做管理对象。下图说明了线程在管理对象之间的流转过程。 注意:线程的流转的状态讨论的是线程调度的过程,并不是线程的状态机。线程的状态机可参考[3],ready_q和wait_q使用可参考[4]。
小节 链接到标题
本文通过分析调度列队管理的实现及线程在列队之间流转,可以看到调度的实际操作就是通过_priq_run_add/_priq_run_remove/_priq_run_best来完成,虽然在[1]中我们可以看到触发调度的时机有很多种,但最后都会走到这三个宏函数。本文是后续分析调度实现代码的基础。